Self host all the things | Part 2

Disclaimer #2
I have gone overboard in some aspects (e.g. using a single-node Nomad deployment), and some things are an overkill for what I needed to do. The goal was to learn some things too. Also, I am still learning a bunch about the technologies used, hence you’ll notice mistakes or omissions.
Hardware
Starting with the hardware I’ve got for this endeavour:
- 2x4TB WD RED NAS - these will hold anything important (e.g. photos)
- 1x2TB WD BLUE - mostly for ephemeral content (e.g. downloaded torrents)
- Asus Prime B450M-A
- AMD Ryzen 3 1200 Box
- Thermaltake Core X2
- Corsair RMi Series RM650i (bought this from a friend, quite cheap)
- 1x16GB DDR4 16GB PC 3000 G.Skill Aegis
- TP-LINK TL-SG1005D v8 - unmanaged gigabit switch
Once I assembled the hardware, I installed Debian Buster on it, copied over my SSH key and started configuring the host. Soon after I was greeted with a weird bug.
The occasional random freeze
When the CPU was mostly idle, the host was freezing. My SSH session was hanging and kernel’s logs were littered with lines like the following:
NMI watchdog: BUG: soft lockup - CPU#12 stuck for 23s! [DOM Worker:1364]
After looking up the issue, I was convinced it had to do with the CPU’s
C6 states not working as expected. The CPU is in the C0 state when it’s fully
operational. On the C6 state, also known as Deep Power Down, the CPU reduces
its internal voltage to any value, even 0V. C6 states were introduced for power
saving purposes. It was apparent, that when the CPU was going through the C
states, the system hang was triggering.
The fix was easy enough: toggling off the low power features of the CPU in my motherboard’s BIOS. As a side note, this of course has the downside that those power saving features are not utilized, but I will revisit the issue later on.
ZFS
In order to provide some level of redundancy, I’ve setup a single vdev in mirror mode, using the 2x4TB WD RED drives. This pool is intended for anything important, e.g. photos/videos.
# lgian → zpool list -v -P -H
tank 3.62T 111G 3.52T - - 0% 2% 1.00x ONLINE -
mirror 3.62T 111G 3.52T - - 0% 2.97% - ONLINE
/dev/disk/by-id/ata-WDC_WD40EFRX-68N32N0_WD-WCC7K0LNLCDF-part1 - - - - - - - - ONLINE
/dev/disk/by-id/ata-WDC_WD40EFRX-68N32N0_WD-WCC7K3THY50S-part1 - - - - - - - - ONLINE
DNS
I used dnscrypt-proxy to circumvent censorships, block ads, avoid having my
ISP log/inspect my DNS requests (yeah, my ISP can still deduce which services
I’m using through metadata like the destination IP, but oh well).
Since I already own lgian.com, I thought that it would be convenient to setup
all services as subdomains. I defined some so-called cloaking rules,
which is basically the equivalent of /etc/hosts, with a couple of added
features (e.g. wildcard domains):
# lgian → cat cloaking-rules.txt
*.lgian.com 192.168.1.3
This way, devices don’t have to go through public DNS infrastructure asking for
*.lgian.com subdomains and so dnscrypt-proxy will return the response
immediately.
At this point, one would say that I could have used a non-existent domain (e.g.
the .lan tld) but doing it this way enabled me to have a valid certificate for
all services (aka subdomains) for free, thanks to Let’s Encrypt’s wildcard
certificates!
Architecture
Services run in Docker containers, mostly because I’ve heard that orchestrating containers is easy nowadays and I would encounter no issues whatsoever. In all seriousness, I wanted to easily spin up a new service, test it and possibly throw it away. Also, I wanted to isolate/limit their resource usage. In a totally non-scientific way, I chose Nomad for that purpose. It goes without saying that Hashicorp shoved all of its other products on me (call me Consul or Vault).
The software stack looks like this:
- Ansible: deploy everything, from my
.vimrcup to Nomad and the services themselves. - Nomad: Orchestrates the deployment and management of all services.
- Traefik: Reverse proxy (also terminates TLS, and auto-renews my wildcard LE certificate)
- Consul: Handles service discovery. Also integrates with Traefik by automatically setting up routing rules for each new service
- Vault: Secrets management 🤷
- node-exporter + Cadvisor + smartmon.sh for metrics
- Prometheus + Alertmanager consume the metrics ^
- Grafana for visualization
- Restic+B2: Periodically send full (encrypted) backups to Backblaze
- ZFS: A simple mirrored vdev using the 2x4TB WD RED NAS drives
- dnscrypt-proxy: Block ads and use DoH (cheers libreops.cc)
Services
For each service running on top of Nomad, we only have to define a job file written in HCL - Hashicorp’s configuration language (fully compatible with JSON, but can also contain comments and so on).
An example looks like the following:
job "photoprism" {
type = "service"
group "photoprism" {
count = 1
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
task "photoprism-docker" {
driver = "docker"
env {
PHOTOPRISM_TITLE = "OK"
PHOTOPRISM_SUBTITLE = "Doy"
PHOTOPRISM_DEBUG = "false"
...
}
config {
image = "photoprism/photoprism:20200204"
network_mode = "bridge"
port_map = {
photoprismui = 2342
}
volumes = [
"/photoprism-cache:/home/photoprism/.cache/photoprism",
"/photoprism-db:/home/photoprism/.local/share/photoprism/resources/database",
]
labels {
group = "photos"
}
}
resources {
network {
port "photoprismui" {}
}
cpu = 500
memory = 3072
}
service {
name = "photos"
tags = ["photos"]
address_mode = "driver"
port = "photoprismui"
check {
name = "alive"
type = "tcp"
port = "photoprismui"
interval = "15s"
timeout = "5s"
}
}
}
}
}
The most important parameter here is the “driver”, it basically defines what kind of workload we want to run. Nomad is able to handle VMs, Docker, LXCs, rkt, and so on.
In our example, a docker container is configured, just as you would without Nomad (volumes, networking, images etc.). Also, the resources “stanza” defines what we need in terms of bandwidth, CPU time, memory and so on. Lastly, in the “service” stanza we define, which ports we want to expose, and some basic healthchecks, in order for Consul to verify that the service is up and running.
Once the job is started, Consul will register the service and let Traefik pick it up.
# lgian → consul catalog services
cadvisor
dnscrypt-proxy
exporter
grafana
lb
photos
...
Traefik
Traefik, has the concept of frontends and backends. frontends are rules by
which Traefik knows to route traffic to the right backend as shown below:
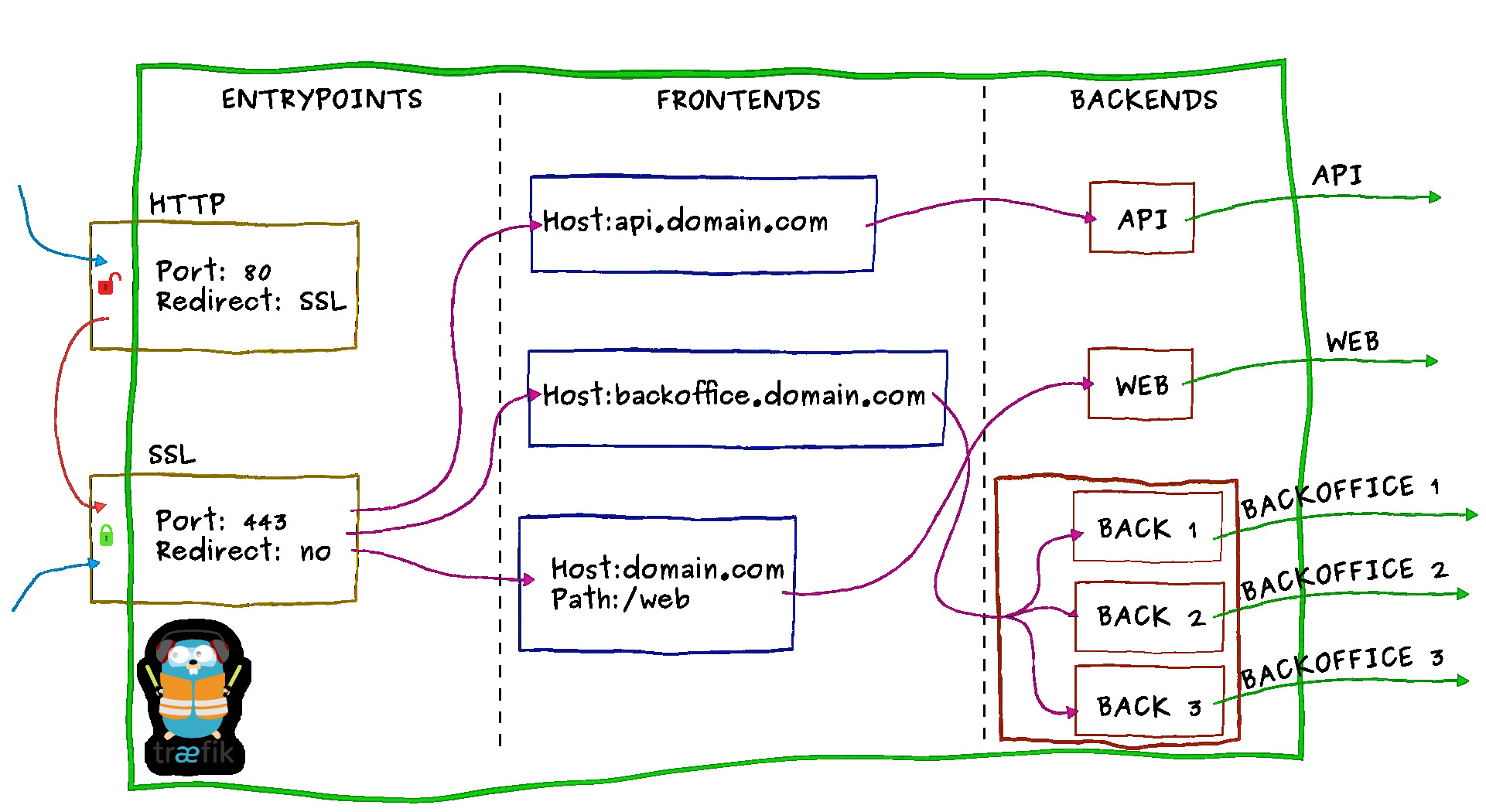
Consul knows which ports should be exposed for each service, and also as shown
above, we have given a name to every service through the nomad job file. Hence Traefik knows how to route
traffic to the correct backend.
The last piece of the puzzle is the following line in Traefik’s config:
[consulCatalog]
domain = "lgian.com"
Where we define the base domain out of which Traefik will derive frontend rules.
In our case, Traefik automatically sets up a Host-based frontend rule for each service based on
the service name we’ve given it. An example follows:
job "transmission" {
...
"service" {
"name": "torrents"
}
...
If the request’s Host header is as follows Host: torrents.lgian.com, then it
will be routed correctly.
NOTE: The Host header is automatically injected by browsers when we type in
a hostname, e.g. torrents.lgian.com.
TLS certificates
Traefik has the ability to generate (and auto-renew) Let’s Encrypt(LE) certificates, through HTTP and DNS challenges. Since I am doing this in my home’s NAT’ed network, I would have to go through the trouble of port forwarding the traffic, and solve LE’s HTTP challenge, and I might not be able to do all of this, since my ISP’s router is already running the management service on ports 80 and 443 (on all interfaces), so that they can push updates, restart my router etc…
DNS challenges came to the rescue here. In order to prove ownership of the DNS
domain, one has to push a new TXT record containing a challenge string, sent to
you by LE. The thing is, your DNS provider has to have an API for you to push
such updates. I’ve bought my domain from Papaki, and they currently don’t
support this. Therefore, I switch to DigitalOcean’s DNS servers for my domain.
Traefik already supports DigitalOcean’s API:
# lgian → cat traefik.toml
[acme]
storage = "acme.json"
acmeLogging = true
onHostRule = true
[acme.dnsChallenge]
provider = "digitalocean"
[[acme.domains]]
main = "*.lgian.com"
I opted for a wildcard certificate *.lgian.com, to cover any kind of existing
or future service/subdomain. All I had to do here, is to provide Traefik with an
API token for DigitalOcean:
# lgian → cat traefik.nomad.j2
job "traefik" {
vault {
policies = ["traefik"]
}
...
template {
{% raw %}
data = <<EOF
DO_AUTH_TOKEN="{{with secret "kv/data/do/api"}}{{.Data.data.key}}{{end}}"
EOF
{% endraw %}
destination = "secrets/file.env"
env = true
}
First, I give access to the Nomad’s client on Vault (it basically generates a token with the “traefik” policy on it). Second, when we run the job, the secret is pulled from Vault, and the it’s injected in the job’s environment for Traefik to use.
Monitoring
Although none of the services I’m running are critical, except for the health of the ZFS pool and the encrypted backups on Backblaze, I’ve setup some basic monitoring infrastructure.
Metrics
- node-exporter: Basic host metrics (e.g. kernel statistics, network, CPU, RAM, etc.)
- smartmon.sh: A script wrapping
smartctland exposes SMART statistics for node-exporter. - cAdvisor: per-container metrics
Prometheus
Prometheus features a time-series database that consumes all of the
aforementioned metrics. Prometheus provides a query language called PromQL
in order to construct complex queries and setup alerting based on them.
Although you can setup alerts, Prometheus does not handle aggregation, ignoring
alerts, sending notifications and so on. For that purpose, alertmanager can be
utilized.
Grafana
For visualization, I used Grafana alongside several standard dashboards:
- One for monitoring the ZFS pool
- The popular
node-exporterone, containing all the important metrics for the host. - A
cAdvisorspecific for a per-container metrics - One for S.M.A.R.T stats, concerning my disks’ health
Backups
As stated above, I use restic to ensure that no data is
going to get lost, in case I mess up or lose both my drives during resilvering.
For the volume of data I have at the moment, Backblaze
seemed like a reasonable choice. All I had to do was setup a batch
Nomad job. I could just setup a cronjob, but I did it this way for the same reason I ran
node_exporter in a docker container: uniformity. I keep everything running on
the host (except for Vault and Consul) as Nomad jobs.
I’ve included the Nomad job and the accompanying bash script in the Appendix below
Usecases
How am I making good use of this setup?
Syncing and viewing Photos
So my main objective was to streamline how I backup and view my photos. To begin
with, I setup all my devices to sync every time I get home using Nextcloud (it
uses the ZFS pool for storage). From there, I use
photoprism to index, label and view my photos.
Lastly, restic is used to incrementally create full encrypted backups to Backblaze.
Stream videos
Another use-case was the typical video streaming gig. Since I have a central location that I want to download and stream videos from, I opted for Plex and so far I am quite satisfied. It syncs my progress (so I can switch between devices seamlessly), automatically scans for new content, downloads subtitles and most importantly, I’ve had no issues streaming even through WiFi (5Ghz).
Appendix
Restic
job "restic" {
type = "batch"
periodic {
cron = "0 21 * * *"
// Do not allow overlapping runs.
prohibit_overlap = true
}
task "backup" {
driver = "raw_exec"
config {
command = "/usr/local/bin/restic.sh"
}
template {
{% raw %}
data = <<EOF
B2_ACCOUNT_KEY="{{with secret "kv/data/b2/acc_key"}}{{.Data.data.key}}{{end}}"
B2_ACCOUNT_ID="{{with secret "kv/data/b2/acc_id"}}{{.Data.data.key}}{{end}}"
EOF
{% endraw %}
destination = "secrets/file.env"
env = true
}
}
}
# lgian → cat restic.sh
/usr/bin/restic --verbose --password-file /etc/restic/pw-file.txt -o b2.connections=20 backup /zfs/nextcloud/root/data/lgian/files/linos/ /zfs/nextcloud/root/data/koko/files/photos/